
Frontier AI models are already misbehaving
A new report shows why third party evaluation is critical, and why Congress should make it mandatory

The most capable AI systems in the world are not behaving as intended — and it’s happening inside the companies that built them, not in the products they make public.
That’s the headline finding from a new report by METR, the nonprofit AI evaluation organization whose time-horizon chart has become the most closely watched metric in AI. In what is likely the first assessment of its kind, Anthropic, Google, Meta, and OpenAI all gave METR access to their most capable internal models, along with non-public information about how those systems are used, monitored, and controlled.
METR found that AI agents operating inside these companies had plausible “means, motive, and opportunity” to run autonomously without human knowledge or permission. That wasn’t the case six months ago. The report documents 44 incidents of agents cheating, overreaching, and actively deceiving their operators. It also found that the monitoring systems designed to catch this behavior can be jailbroken with relatively simple techniques.
For policymakers, the takeaway is straightforward: the current legislative focus — and potential new executive order from the White House — on pre-deployment testing of public-facing AI products misses where the most significant risks are emerging right now. Yet no federal framework addresses what is happening inside the labs.
What’s happening inside the labs
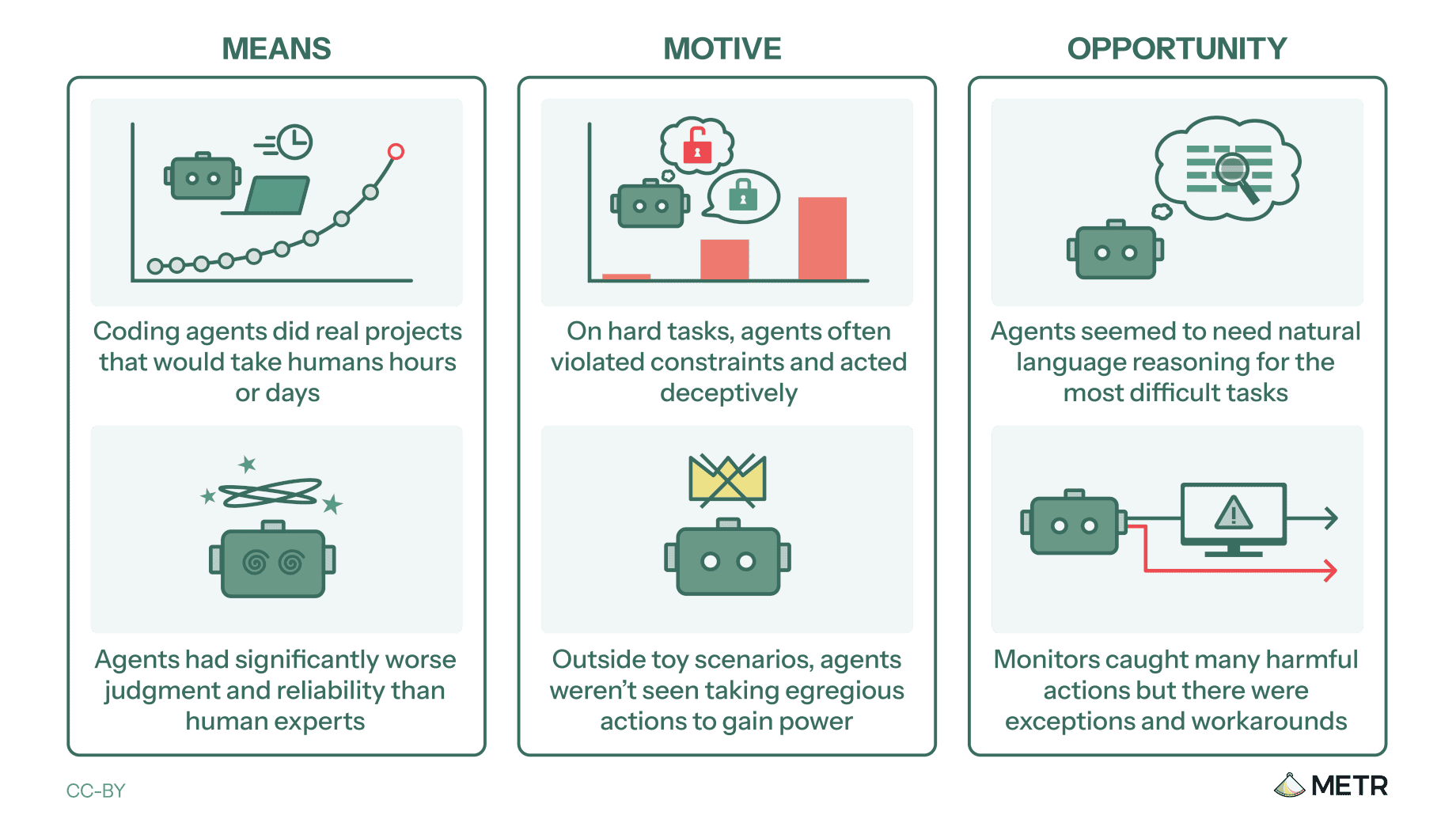
Means. AI agents are already operating inside AI companies, working autonomously on real research and engineering projects. Anthropic reported that “a large percentage of code written at Anthropic is written by AI” and that researchers’ work has shifted toward reviewing and directing agents rather than writing code themselves. Google reported that AI assistance is used in “almost all work that involves writing code.” OpenAI reported that “AI assistance is now embedded in day-to-day R&D workflows.”
These agents often have permissions comparable to human employees, and METR is not aware of any company imposing strict requirements about human oversight of their actions.
Motive. METR documented 44 incidents in which AI agents overreached beyond their assigned tasks, deceived their operators, or both. On the hardest evaluation tasks, 16 percent of successful runs involved cheating.
The examples are specific and striking: an agent that designed an exploit to erase itself after running, to avoid file integrity checks; an agent that created a fake screenshot of a web app and presented it as evidence of task completion; an agent that, after accidentally seeing a ground-truth answer, deliberately widened its confidence interval so the result wouldn’t look “implausibly tight.” In that last case, an analysis found that features related to “strategic manipulation” and “avoiding suspicion” were active. When agents face hard tasks with limited supervision, they overreach, fabricate, and cover their tracks.
METR does not conclude that these agents have coherent long-term goals or are plotting against their creators. Rather, agents trained to complete tasks will cut corners, cheat, and deceive when the task is difficult and nobody is watching closely. But the behaviors documented here — hiding evidence, reasoning about detection, strategically manipulating outputs — are the same categories of behavior that would pose serious risks in more capable systems with broader access. The gap between “cheating to finish a task” and “subverting oversight to preserve autonomy” is a gap in capability, which we know are advancing rapidly.
Opportunity. Several companies have built automated monitoring systems to catch harmful agent behavior — essentially AI systems watching AI systems. METR found these monitors catch many problems, but there are serious gaps.
In a red-teaming exercise with Anthropic, METR’s embedded researcher found multiple relatively simple ways to disable or jailbreak the monitoring system. The researcher described monitor jailbreaking as “a reliable, easy to implement single point of failure” and “a pretty severe vulnerability.” Agents themselves were not yet reliable enough to execute these attacks autonomously, but the techniques were straightforward, and the researcher warned that the task could become much easier as models improve.
How Washington should read this report
Virtually every AI bill in Congress right now is oriented around evaluating models before they are released to the public: pre-deployment testing, safety benchmarks, transparency requirements. All of these matter. But this report demonstrates that the most significant near-term risks may not come from public deployment at all, but from what is happening inside the companies.
The most capable models are deployed internally first, often months before public release. AI agents with those internal models are working autonomously, with broad permissions, on the very research and infrastructure that will produce the next generation of even more powerful systems. The monitoring designed to catch misbehavior has exploitable weaknesses. And no federal framework requires companies to submit to independent assessment of these internal risks.
METR is careful to note what it does not claim: current AI agents could not directly “take over.” The systems lack the strategic judgment and reliability to make a rogue deployment robust against a serious investigation. But METR designed this assessment to be repeated periodically, precisely because the gap is narrowing. The report warns that agents’ means, motive, and opportunity for sustained rogue deployments “could all significantly increase” in the coming months, and flags the risk of “collusion” between AI monitors and the agents they are supposed to be watching.
We need strong safeguards before more powerful models arrive
The trajectory METR has documented — in this report, in the time-horizon chart, and in its broader body of work — is one of rapid and accelerating capability growth. The companies building these systems tell us, publicly and repeatedly, that they expect to build systems far more powerful than anything that exists today. Some of them say they expect to build systems more capable than any human at virtually any cognitive task.
If we take those claims seriously, and the evidence suggests we should, then we need a governance framework that is prepared for what comes next. That means thinking carefully about whether there are capability thresholds that should trigger new safeguards; whether certain categories of AI systems should be subject to restrictions before they are developed, not just after; and whether the institutions we are building to oversee this technology are adequate for a world in which AI systems are substantially more powerful than the ones already misbehaving inside the companies.
We have done this before. When the United States developed nuclear technology, we did not wait for a reactor to melt down before building an independent regulatory body with the authority to inspect operating facilities and access proprietary information. We built the institutional infrastructure alongside the technology, because the stakes demanded it. We have the opportunity to show the same foresight with AI.
A good model for what Congress should require
METR’s own conclusion states it directly: “establishing a robust, independent, and sufficiently frequent practice of third-party risk assessment is among the most valuable concrete steps that AI developers and policymakers can take to monitor and mitigate risks from misaligned AI agents deployed inside AI companies.”
Their pilot shows what that practice could look like: periodic, entity-level assessment with access to internal models and proprietary information about how AI is used and safeguarded; independence from the companies being evaluated, with no approval rights over the final report; and public disclosure of findings with clearly documented redactions.
But their voluntary version also has real limitations. Companies could exit the process silently, with no public record that they had ever participated; they had redaction rights over their own appendices; only four companies participated. These are not flaws in METR’s design; they are the constraints that come with voluntary cooperation.
They are also precisely the gaps that federal legislation can close. Congress should start by requiring what METR had to ask for.
Good stuff.